rhoadley.net music research software blogs
aru seminars m&t critski focm1a cmc circuit bending mic2b sensor technology comp 3 sonic art major project
youtube vimeo facebook
Resources: Bioacoustics Jitter MaxMSP OSC Physical PD CBHH sTech SuperCollider C/Xcode
Max/MSP Resources: Home Blog-wp Forum Examples Projects Tasks Tutorials
Max/MSP Tasks
The Voice Task
| Task 4 | Name: The Voice Task | Set: w4i | Due: w5i | Weighting: 0% | Courses: cmp |
| Prev Task: Fiddle Bonk Gate Task | Next Task: Generative Composition Using SC 1 - GUI | ||||
| Task Summary | All CMP tasks | WebCT | |||
A look at a number of speech based synthesisers and editors.
To Cover
- Speech managers
For some reason speech managers seem to come in and out of fashion with regularity. The below should work with PPC Macs and Max 4.x, but not with Intel or Max 5.x. However, I'll leave them here for you to investigate if you like:
- MBrola is a public-domain voice synthesiser. A version of the MBrola engine has been rendered for use in Max/MSP. There's an object available for MaxMSP (only for PPC Macs, though) here.
- Flite~ is another object avaible for MaxMSP on PPC Macs here or for Pure Data here.
- VQCLib - Voice Control Quality from Nicholas d'Alessandro.
- fofb~, fog~... (IRCAM)
The following should work with both Intel and PPC Macs and with MaxMSP v5.x. It may take a while to sort out some of them, so don't leave things until the last minute!
- aka.speech, a part of the aka.objects.
- aka.listen, a part of the aka.objects - careful here, the object can be a bit flaky...
The following requires you to download and install the relevant version of Csound.
- vSynth - a part of UBCToolbox, utilising fofs in Csound
- MaxMSP Csound~ object - NB this is one of two, the other is by Matt Ingals.
- Csound itself is here - you need to be careful with the versions!
- The Canonical Csound Reference Manual
- Csound Tutorials
MBrola
Mac/PPC Only
Make sure you have a functional understanding of the MBrola software. If necessary, load a number of phoneme databases (MBrolix/Preferences/Add Voices) and test each with a phoneme file appropriate for the voice. Feel free to experiment.
A Sample File
; Mbrola demo file for en1.
_ 50
e 40 0 102
m 50
b 50
r 30
@U 80 5 119 35 126 70 140
l 50
@ 50 50 173
w 100 75 133
#
Explanation
- _ 50 - a pause for 50ms
- e 40 0 102 - the vowel e (actually translates as a position within the audio file 'en1'. 40 reprepresents the length - alter this to 400 to hear a marked difference. The 0 represents the percentage of the audio file from the e is taken. 102 represents frequency.
- The final hash clears the buffer - it's useful when you want to terminate a diphone.
The Voice Database Format
- Signed 16 bit PCM
- Little-endian
- Mono
- 16000Hz
Voice/Vocal synthesis - Chant, fof, etc.
Mac PPC only: using fog~ and fofb~ objects from IRCAM.
aka Objects
Universal Binary
For most of you, this is the safest and most straightforward option. Experiment with the patch(es) and go through the helpfiles.
vSynth/UBCToolbox/CSound
vSynth - a part of UBCToolbox, utilising fofs in CSound
This will currently only apply to those who have their own machines. As implied above, you need to install CSound5 and the UBCToolbox (links above). These are a complex set of tools, including a couple of synths (vSynths) which utilise CSound's fof opcodes to generate effective vocal sounds live. If you have access to the necessary equipment (PPC/Intel Mac and Windows) please feel free to have a go at this: the software is all free!
Speech in SuperCollider
Not officially what we're doing, but you might be interested in playing with this. Open a new patch in SuperCollider. Type in Speech and draw up the help file. Investigate. (But be careful. Using the voice manager in either MaxMSP or SuperCollider seems to cause many crashes, etc...
The TaskChoosing one or more of the above methods, follow these instructions: Using MBrola and/or any of the other methods (Flite~, aka.speech/listen, vSynth, SuperCollider, etc.)
Finally
|
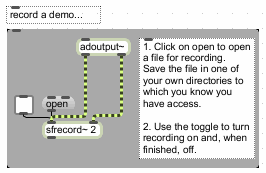
You might also be interested in:
- Speech in SuperCollider
- The MBrola Project
- Fof objects (see IRCAM externals)
More information (not really processed yet, but feel free to have a look)
http://tcts.fpms.ac.be/synthesis/mbrola/mbruse.html#PHONETIC
The input file bonjour.pho supplied as an example with FR1 simply contains :
_ 51 25 114
b 62
o~ 127 48 170
Z 110 53 116
u 211
R 150 50 91
_ 91
This shows the format of the input data required by MBROLA. Each line contains a phoneme name, a duration (in ms), and a series (possibly
none) of pitch pattern points composed of two integer numbers each : the position of the pitch pattern point within the phoneme (in % of its
total duration), and the pitch value (in Hz) at this position.
Hence, the first line of bonjour.pho :
_ 51 25 114
tells the synthesizer to produce a silence of 51 ms, and to put a pitch pattern point of 114 Hz at 25% of 51 ms. Pitch pattern points define a
piecewise linear pitch curve. Notice that the pitch pattern they define is continuous, since the program automatically drops pitch information
when synthesizing unvoiced phones.
The data on each line is separated by blank characters or tabs.Comments can optionally be introduced in command files, starting with a
semi-colon(;). A comment begining with "T=ratio" or "F=ratio" changes the time or frequency ratio respectively.
Notice, finally, that the synthesizer outputs chunks of synthetic speech determined as sections of the piecewise linear pitch curve. Phones
inside a section of this curve are synthesized in one go. The last one of each chunk, however, cannot be properly synthesized while the next
phone is not known (since the program uses diphones as base speech units). When using mbrola with pipes, this may be a problem. Imagine, for
instance, that mbrola is used to create a pipe-based speaking clock on an HP :
speaking_clock | mbrola - -.au | splayer
which tells the time, say, every 30 seconds. The last phone of each time announcement will only be synthesized when the next announcement
starts. To bypass this problem, mbrola accepts a special command phone, which flushes the synthesis buffer : "#"
|
The MBROLA synthesiser is controlled by means of command files. These files contain the following information: * phonetic transcription, using phonemes and allophones * durations of phonemes and allophones * pitch points, i.e. turning points in a stylised pitch contour * optional: comment Information about the 53 phoneme and allophone symbols for this Dutch database is available in a separate table (http://www-uilots.let.uu.nl/~Hugo.Quene/onderwijs/lotsummer98/nl2.txt). This is an example of a command file for the Dutch utterance Hallo!: ; Utterance: "Hallo!" _ 100 100 120 h 96 A 48 l 76 5 100 75 120 o 224 25 85 _ 100 40 70 The first line is comment. Comment lines start with a semicolon (;). The other lines contain the following information: * 1st column: phoneme or allophone segment. The "underscore" represents silence; each utterance begins and ends with a silence symbol. * 2nd column: duration of the segment. The utterance starts with a silence of 100 ms duration. The initial [h] has a duration of 96 ms, [A] lasts 48 ms, etc. * remainder: zero or more pitch points. Each pitch point is indicated by two numbers. The first number of the pair indicates the position, in time, expressed as a percentage of the segmental duration. The second number of the pair indicates the pitch in Hz. More about diphones Diphones are short fragments of speech, recorded and processed. When you are synthesising an utterance, the appropriate diphones are taken from the database, concatenated, given the requested duration and intonation (using a PSOLA-like procedure), and con verted to sound. Hence, end users of the synthesizer have no control over the degree of assimilation in the output speech. We have to wait and hear to what extent the original speaker of the database has applied coarticulation or assimilation in the speech fragments. We c an, however, request certain phonemes in the phonetic transcription, thus forcing the synthesizer to 'complete' assimilation. 1. A bad example Copy the command file zoutzuur.pho to your diphone directory, and synthesise this file with the command dsyn zoutzuur. What is wrong with it? Inspect the command file, with a text editor or with the Unix command cat zoutzuur.pho. 2. You can do better Open the command file zoutzuur.pho in a text editor. [*] Adjust the durations of the critical VCCV segments. Save the file, and synthesize it again. Do both realisations sound perfect to your ears? If not, go back to the point marked [*] above. W hat is the ratio between C and V2 durations, in both realisations? What is the sum of their durations? 3. Now on your own Using the now perfect file zoutzuur.pho as an example (e.g. for the pitch contour), your task is now to make synthetic versions of all utterances which were measured in session 2. Make versions both with (complete) assimilation, and without assimilation. (Use the phoneme table to determine the appropriate transcription symbols). Do this for corresponding 'viable' and 'unviable' cases. Compare the synthetic versions with the natural ones. You can even specify the 'natural' segment durations in the command files. How does that affect the perceived segmentation? Last updated on June 24, 1998, by Hugo Quen. |
http://www.phon.ucl.ac.uk/courses/spsci/spc/
2.2. NU-MBROLA synthesis The NU-MBROLA synthesis engine performs synthesis with the standard MBROLA algorithm [12] but it is no longer limited to diphone-based synthesis. As opposed to the MBROLA databases and synthesis engine, which embody acoustic and phonetic information, both the NU-MBROLA databases and the NU-MBROLA engine are purely acoustic objects. Units could thus be words, syllables, phonemes, or any other type of speech segment). NU-MBROLA need not know about this. Examples of use are presented in section 3 on unit selector. For synthesis, the user provides the list of speech segments to be concatenated and produced with some target prosody. Speech segments are defined by their location in the original speech corpus, with their starting and ending points in milliseconds. Target prosody must then be defined as in the MBROLA .pho file format : duration (in milliseconds) followed by optional pitch pattern point definitions (each point being defined by its position in percent in the target duration and target pitch value in Hz). An example of NUMBROLA input format is: snd01.wav 253 289 45 10 119 21 112 snd01.wav 123 189 56 snb09.wav 5078 5096 100 99 120 This will produce 201 ms of synthetic speech, using 3 units taken from 2 separate files, and applying a pitch movement that goes from 112 Hz (at 10% of the 45 ms of the first segment) to 120 Hz (at 99% of the .100 ms of the last segment). Intonation is linearly interpolated from pitch pattern points in a log scale. During synthesis stage, speech segment descriptions (with references to the original speech files) are translated into NUMBROLA segment descriptions and are extracted from the NU-MBROLA database. Synthesis is performed by the standard MBROLA algorithm imposing the target prosody features. Duration modification is uniform (i.e., the duration scaling factor is constant) throughout each speech segment. Some smoothing can advantageously be performed to reduce the spectral differences at segment boundaries. Consecutive segments (regarding their location in the original speech corpus) naturally exhibit some spectral differences but these differences correspond to the natural evolution of speech and need to be preserved. Therefore, smoothing is only performed at stable and voiced boundaries of nonconsecutive segments by distributing linearly the difference of boundaries frames in the right and left stationary frames by a fading/fadeout operation. Since the NU-MBROLA corpus is composed of constant length frames with constant phase envelopes (for low ordered harmonics), sample by sample subtraction of boundary frames provides the difference frame. Linear distribution of this difference frame corresponds to distributing the spectral difference linearly. |
The Projects
The projects and tasks are designed to help you through the various courses and materials that you'll have to deal with, and also to provide an active and practical element to what could otherwise become a rather dry and technical exercise. Tasks are small exercises - you may be asked to complete one or two per week. Projects are larger and carry a higher percentage of the mark. We will undertake two, three, four or more projects and tasks. The final project is usually an individual choice project, and will be worth significantly more than the others in terms of percentages in your portfolio. We will usually try to set aside a time to perform the projects in a public setting.